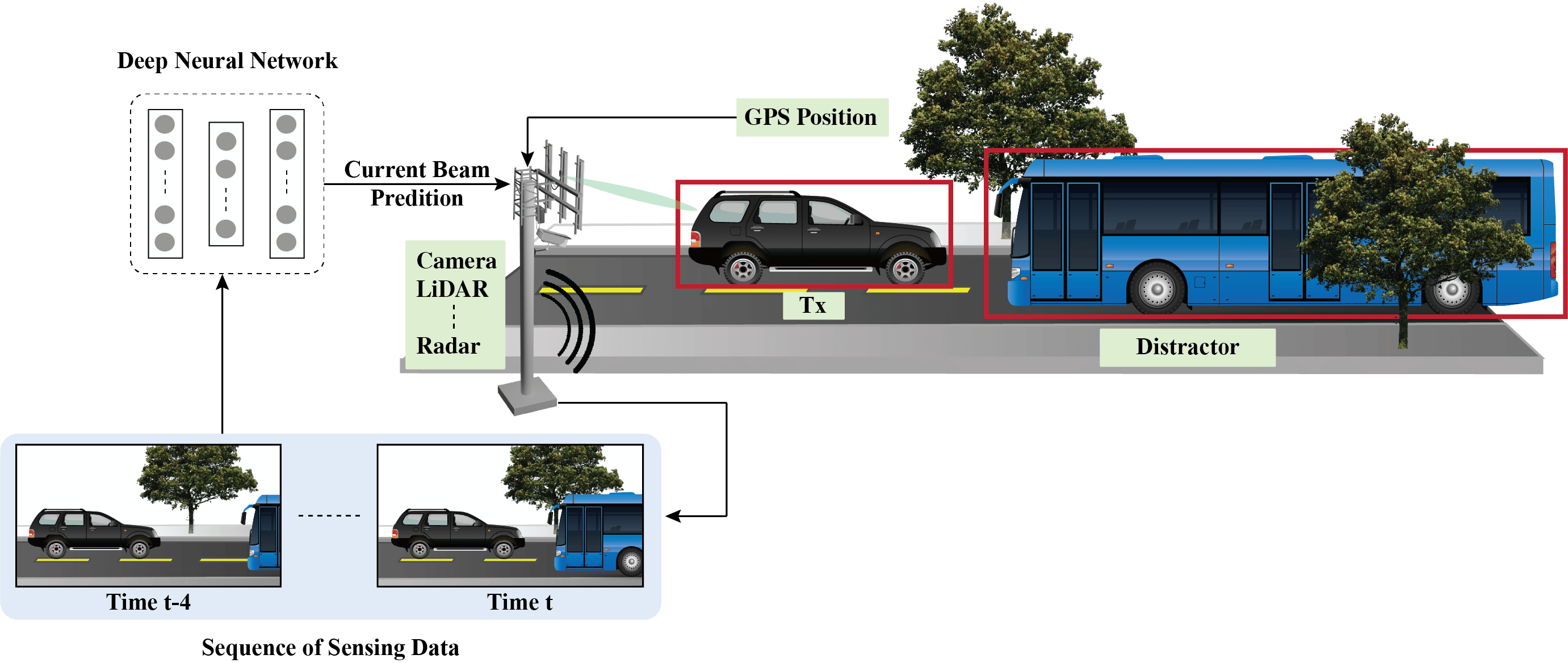
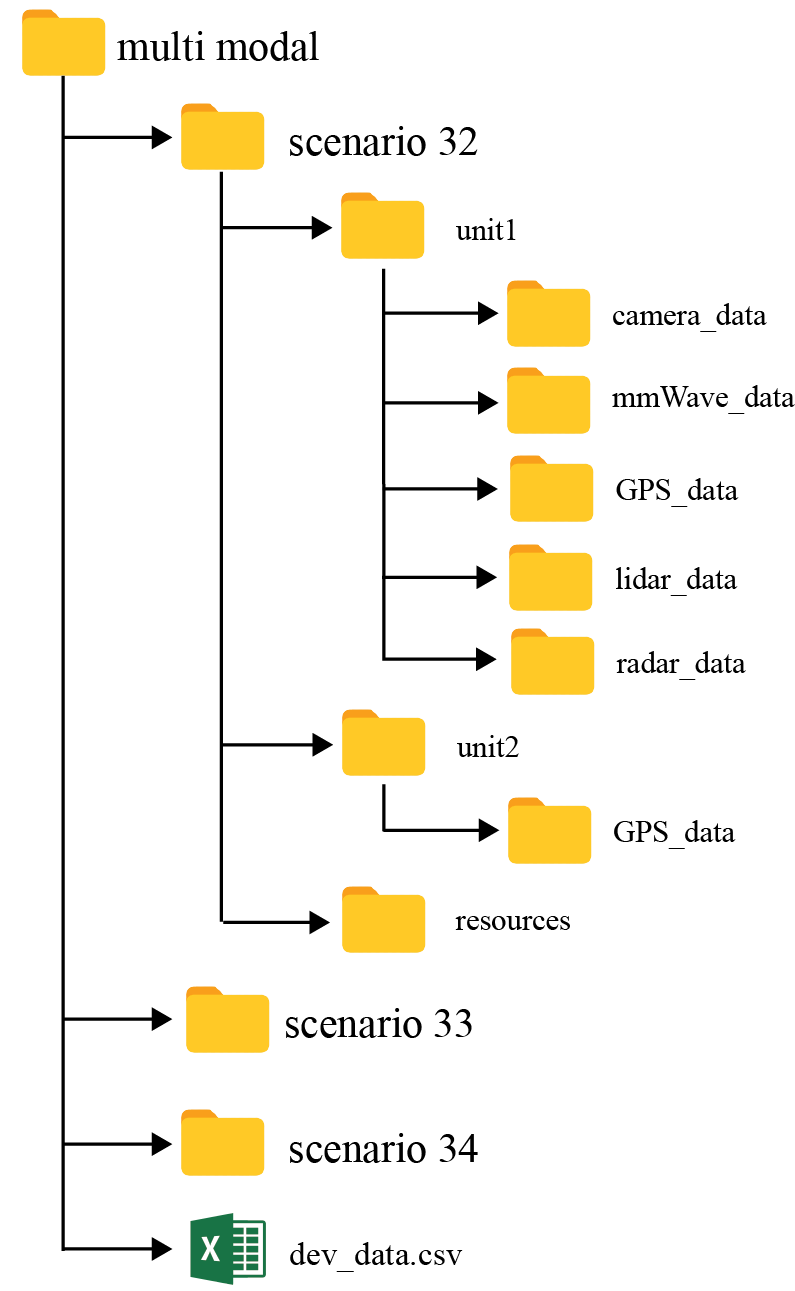Beam selection is a challenge: Current and future communication systems are moving to higher frequency bands (mmWave in 5G and potentially sub-terahertz in 6G and beyond). The large available bandwidth at the high frequency bands enables these systems to satisfy the increasing data rate demands of the emerging applications, such as autonomous driving, edge computing, and mixed-reality. These systems, however, require deploying large antenna arrays at the transmitters and/or receivers and using narrow beams to guarantee sufficient receiver power. Finding the best beams (out of a pre-defined codebook) at the transmitter and receiver is associated with high beam training overhead (search time to find/align the best beams), which makes it difficult for these systems to support highly-mobile and latency-sensitive applications.
Sensing aided beam prediction is a promising solution: The dependence of mmWave/ THz communication systems on the LOS links between the transmitter/receiver means that the awareness about their locations and the surrounding environment (geometry of the buildings, moving scatterers, etc.) could potentially help the beam selection process. To that end, the sensing information of the environment and the UE could be utilized to guide the beam management and reduce beam training overhead significantly. For example, the sensory data collected by the RGB cameras, LiDAR, Radars, GPS receivers,etc., can enable the transmitter/receiver decide on where to point their beams (or at least narrow down the candidate beam steering directions).
Towards real-world deployment: Recent work on sensing-aided beam prediction has shown initial promising results in utilizing the sensory data such as RGB images, LiDAR, radar and GPS positions for the beam prediction problem. However, these solutions were mainly trained and tested on the same (mainly synthetic) datasets. To take these interesting ideas one step towards real-world deployments, we need to answer the following important questions: (i) Can sensing-aided beam prediction solutions perform well on real-world data? and (ii) Can the developed ML models that are trained on certain scenarios generalize their beam prediction/learning to new scenarios that they have not seen before?
Figure 1: Representation of the sensing-aided beam prediction task targeted in this challenge
Problem Statement
This ML challenge targets addressing the important questions mentioned above. In the challenge, the participants are asked to design machine learning-based solutions that can be trained on a dataset of few scenarios and then generalize successfully to data from scenarios not seen before.
Objective: Given a multi-modal training dataset consisting of data collected at different locations with diverse environmental features,the objective is to develop machine learning-based models that can adapt to and perform accurate sensing-aided beam prediction at an entirely new location (not part of the training dataset).
With the objective mentioned above, the primary track in this challenge is Multi-Modal Sensing-Aided Beam Prediction.
For this, the task entails observing a sequence of sensory data captured at the basestation to predict the current optimal beam indices from a pre-defined codebook. Along with the sequence of the sensing data (i.e., image, LiDAR and radar), we also provide the ground-truth GPS locations (latitude and longitude) of the transmitter in the scene for a subset of the sequence. The scenarios selected for this challenge are primarily multi-candidate, i.e., more than one object is present in the wireless environment. One approach can be to first identify the transmitter in the scene. For this, the positional data can be utilized.
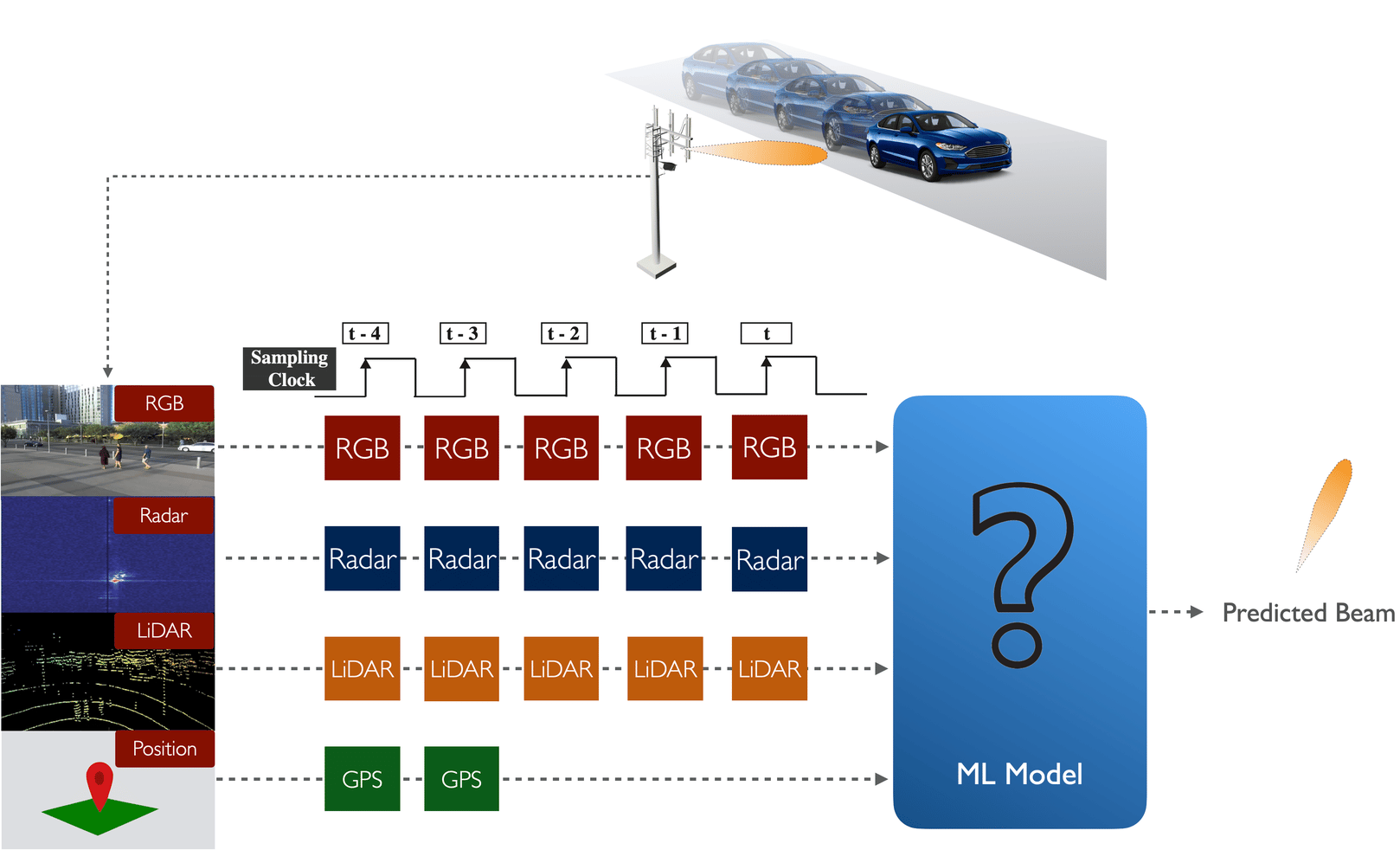
Figure 2: Schematic representation of the input data sequence utilized in this challenge tasks
Problem Statement: As shown in Fig. 2, at any time instant t, a sequence of 5 samples (current and previously observed sensing data, i.e., [t-4, …, t]) is provided. We also provide the ground-truth GPS locations of the user for the first two samples in the sequence, i.e., time instants t-4 and t-3. Participants are expected to design a machine learning solution that takes this data sequence and learns to predict the optimal beam index at time t.
Note: The participants are free to utilize either all the data modalities or a subset of the data modalities.
We formulate this problem in this way to mimic a real-world scenario where not all the modalities (especially position) are available at all the samples. In reality, the position information may be captured by the user and then transmitted back to the basestation for downstream applications. Hence, the position data might not be available for every time instance and may be subject to additional delays. Further, the sampling frequency of GPS sensors could, in practice, be less than the sampling rate for the other modalities.
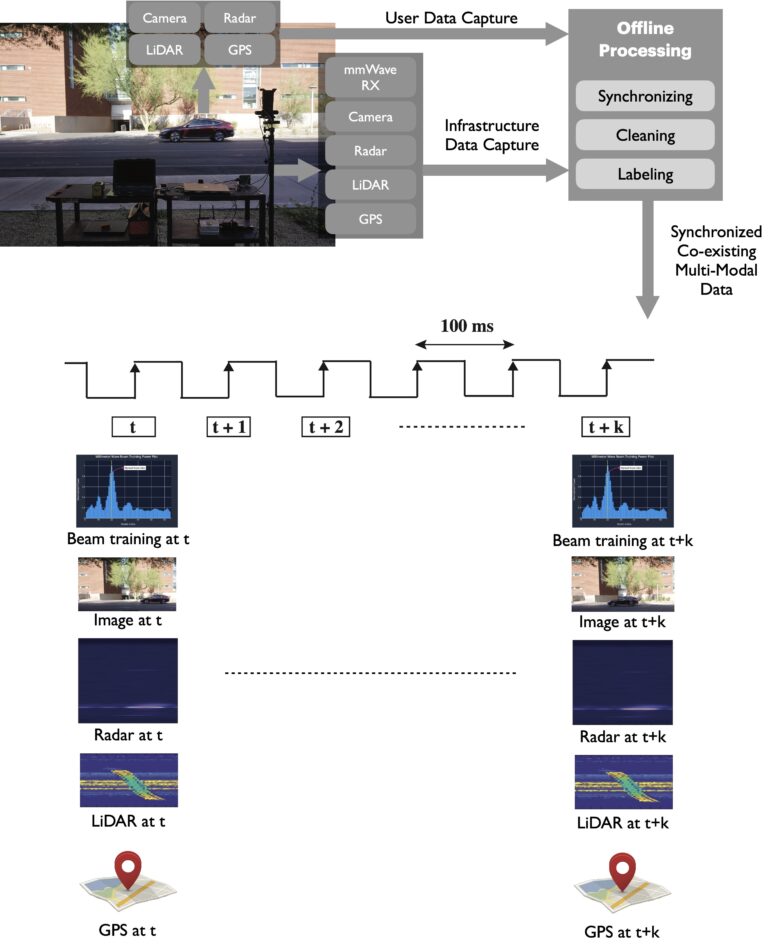
Developing efficient solutions for sensing-aided beam prediction and accurately evaluating them requires the availability of a large-scale real-world dataset. With this motivation, we built the DeepSense 6G dataset, the first large-scale real-world multi-modal dataset with co-existing communication and sensing data. Fig. 3 highlights the DeepSense 6G testbed and the overall data collection and post-processing setup.
Figure 3: This figure presents the data collection testbed used for this data collection and the post-processing steps utilized to generate the final development dataset
In this challenge, we build development/challenge datasets based on the DeepSense data from scenarios31 – 34. Please follow the links below to learn more about each scenario.
Each scenario dataset, comprises of the GPS position of the user,RGB images, radar and LiDAR data, the corresponding 64×1 power vectors obtained by performing beam training with a 64-beam codebook at the receiver (with omni-transmission at the transmitter). The LiDAR, radar and visual data are captured by the sensors installed at the basestation. The positional data is collected from the GPS receivers installed on the mobile vehicle (Tx).
Development Dataset
The primary goal of this challenge is to study the generalizability of the sensing-aided beam prediction solutions. With this motivation, we generate the final challenge training and test dataset.
Training Dataset: The majority of the training dataset comprises of dataset from three scenarios 32 -34.
Test Dataset: 50% of the test dataset is from scenarios 32- 34 and the remaining 50% is from the unseen scenario 31.
In this challenge, we have one primary track Multi-Modal Beam Prediction. However, participants can select a subset of these data modalities and design the ML solution based on them. For easier access to the datasets, we also provide the following sub-datasets: (i) vision-position, (ii) LiDAR-position and (iii) radar-position. For the other dataset combinations, please use the multi-modal dataset comprising all the modalities.
For each of the sub-datasets, we provide the respective modality data with the ground-truth beam indices. The multi-modal beam prediction track includes all the data modalities. For example, in the multi-modal beam prediction track, we provide the following:
Training Dataset: Each data sample comprises of the sequence of 5data samples (image, LiDAR and radar) and the ground-truth GPS locations of the transmitter for the first two instances in the sequence. We also provide the 64×1 power vector corresponding to the 5th sample in the sequence obtained by performing beam training with a 64-beam codebook at the receiver (with omni-transmission at the transmitter). The dataset also provides the optimal beam indices as the ground-truth labels.
Test Dataset:To motivate the development of efficient ML models, we provide a test dataset, consisting of only the sequence of 5 input data samples, i.e., sequence of 5 visual, LiDAR and radar data. The ground-truth labels are hidden from the users by design to promote a fair benchmarking process. To participate in this Challenge, check the ML Challenge section below for further details.
For the sub-datasets, i.e., vision-position, radar-position, and LiDAR-position, we only provide the data for the primary modality along with the corresponding GPS data of the user in the scene for the first two instances in the sequence. For example, in the radar-position sub-dataset, only the sequence of 5 radar samples (with the GPS positions for the first two instances in the sequence) is included. Similarly, in vision-position and LiDAR-position, we provide the sequence of 5 image samples and LiDAR data, respectively.
Step 2.Extract the zip file. Contains the development dataset
Each development dataset consists of following files:
scenario folders: As mentioned earlier, the development dataset (provided for training and validation) comprises of data from the three DeepSense 6G scenarios: (i) scenario 32, (ii) scenario 33 and (iii) scenario 34. Each of the scenario folder comprises of the following sub-folders:
unit 1: Includes the data captured by unit 1 (basestation). For the multi-modal dataset, it includes all the modalities, i.e., camera_data, lidar_data and radar_data. However, for the sub-datasets, the unit 1 folder only includes the particular modalities. For example, in radar-position sub-dataset, the unit 1 folder only contains the radar data (along with the unit1 GPS data and the mmWave receive power data).
unit 2: Includes the data captured by unit 2 (vehicle). For these scenarios, it is the ground-truth GPS location of the UE (vehicle).
dev_data.csv: The csv file is described below.
What does each CSV file contain?
For each data sample (data point), we provide a sequence of 5 input samples (image, radar and LiDAR) that correspond to 5 time instances along with the ground-truth locations for the first two instances. We, also, provide the ground-truth power vector (64×1) for the 5th instance. Further, we compute the ground-truth beam indices from the power vectors and provide them under the “beam_index” column. An example of 4 data samples in shown below.
File could not be opened. Check the file's permissions to make sure it's readable by your server.
Baseline and Starter Script
Baseline Solution
In the challenge dataset, a sequence of 5 input samples are provided along with the ground-truth locations for the first two instances. The participants are expected to predict the optimal beam indices corresponding to the 5th data samples in the sequence. As a baseline solution, we utilize only the two ground-truth user GPS locations provided in each data sample to predict the future beam at the 5th time instance.
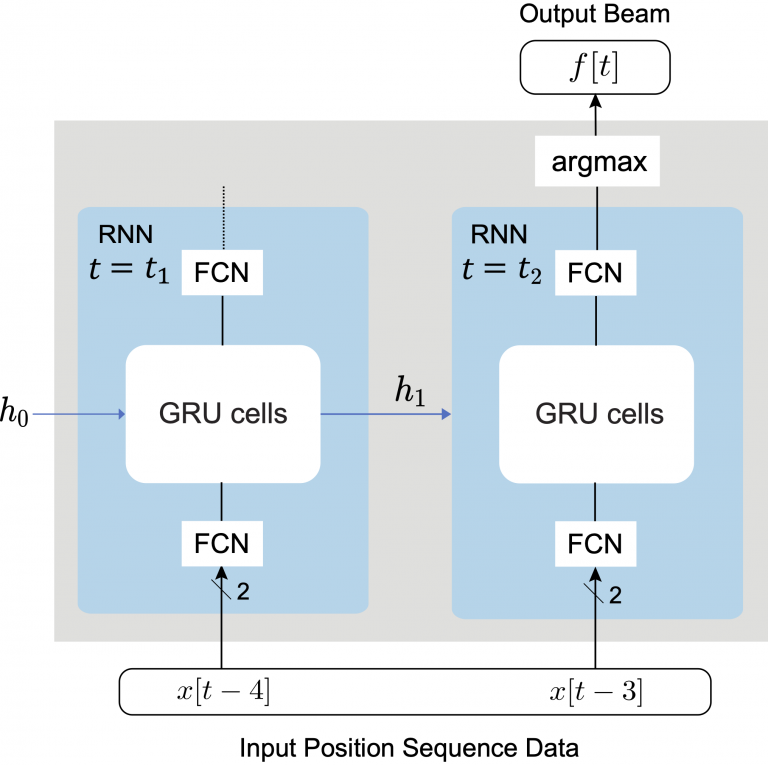
The proposed solution utilizes a two-stage LSTM network, followed by a fully-connected layer acting as a classifier. More specifically, the model receives a sequence of 2 positions (for the 1st and 2nd time instances) as input and predicts the optimal beam at 3 steps in the future (at the 5th time instance).
Figure 4: This figure presents the proposed position-aided future beam prediction solution.
If you want to use the dataset or scripts in this page, please cite the following two papers:
A. Alkhateeb, G. Charan, T. Osman, A. Hredzak, and N. Srinivas, “DeepSense 6G: large-scale real-world multi-modal sensing and communication datasets,” to be available on arXiv, 2022. [Online]. Available: https://www.DeepSense6G.net
@Article{DeepSense, author = {Alkhateeb, A. and Charan, G. and Osman, T. and Hredzak, A. and Srinivas, N.}, title = {{DeepSense 6G}: Large-Scale Real-World Multi-Modal Sensing and Communication Datasets}, journal={to be available on arXiv}, year = {2022}, url = {https://www.DeepSense6G.net},}
G. Charan, U. Demirhan, J. Morais, A. Behboodi, H. Pezeshki, and A. Alkhateeb, “Multi-Modal Beam Prediction Challenge 2022: Towards Generalization,” available on arXiv, 2022. [Online]
@Article{DeepSense_Challenge, author = {Charan, G. and Demirhan, U. and Morais, J. and Behboodi, A. and Pezeshki, H. and Alkhateeb, A.}, title = {Multi-Modal Beam Prediction Challenge 2022: Towards Generalization}, journal = {arXiv preprint arXiv:2209.07519}, year = {2022},}
Competition Process
Participation Steps
Step 1. Getting started: First, we recommend the following:
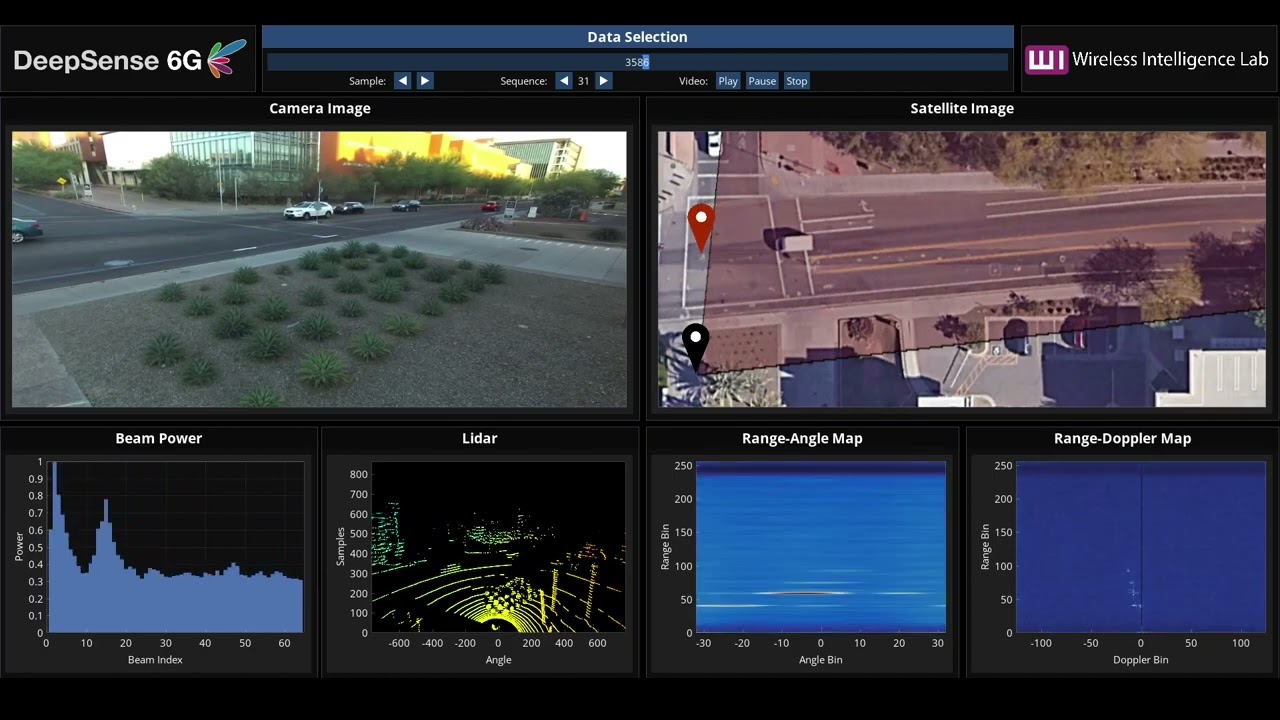
Get familiarized with the data collection testbed and the different sensor modalities presented here
Next, in the Tutorialspage, we have provided Python-based codes to load and visualize the different data modalities
Step 2. Problem Statement: Read the problem statement of the multi-modal sensing-aided beam prediction task
Step 3. Development dataset: You can download the dataset from the ITU competition page (after registration).
Step 4.Submission: After you develop your ML model, please submit your results using your ITU dashboard. Please find the submission process and evaluation criteria below.
Submission Process
The objective is to evaluate the beam prediction accuracy and the ability to generalize to unseen scenarios. For this objective, we will release the test set before the end of the competition. This test set contains a mix of data samples: (i) 50% of the test samples are from the scenarios present in the training set, and (ii) 50% of the samples are from a similar but different scenario (not part of the training set). Participants should use their ML models to predict the top 3 optimal beam indices for the test dataset and send the results in a CSV file format.
The users must submit the Top-3 predicted beams for the Challenge set. An sample submission csv file is shown below.
Every submission should include the pre-trained models, an evaluation code and a ReadMe file documenting the requirements to run the code. Participants are encouraged to make their results as easy to reproduce as possible, e.g. by providing a single entry point to a predefined Docker image. Any submission that cannot be reproduced because of issues with setup, dependencies, etc. won’t be considered valid.
File could not be opened. Check the file's permissions to make sure it's readable by your server.
Evaluation
The evaluation metric adopted in this challenge is a “Distance-based Accuracy Score (DBA-Score)”. For this, we utilize the top-3 predicted beams.
The DBA-Score is defined as :
Rules
To participate in this challenge, the following rules must be satisfied:
Participants can work in teams up to 4 members (i.e., 1-4 members). All the team members should be announced at the beginning (in the registration form) and will be considered to have an equal contribution.
There are no constraints on the participants country (participants from all countries are invited).
The participation is not limited to undergraduate students (graduate students are also invited).
The participation is not limited to academia (participants from industry and government are also invited).
Solutions must be trained only with samples included in the training dataset we provide. Data augmentation techniques are allowed as long as they exclusively use data from the training dataset. However, it is not allowed to use additional data obtained from other sources or public datasets.
Timeline and Prizes
Timeline
Registration: June 20, 2022 – September 30, 2022
Release of the development dataset: June 20, 2022
Release of the test dataset: October 1, 2022
Submission deadline: October 28, 2022
Final ranking (and announcing the winners): November 10, 2022
Grande challenge finale: November – December, 2022
Prizes
1st winner: A cash prize of$4000
2nd winner: A cash prize of$2000
3rd winner: A cash prize of$1000
The top 3 teams will also be invited to co-author a paper together with the organizers on multi-modal sensing aided beam prediction.